2020-2-4 DB Sharding
샤딩
- 샤딩이란 테이블에서 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법
- 1~100개의 row가 있을때, 1~50은 1번 DB, 나머지를 2번 DB에 저장하면 Horizontal Partitioning으로 볼 수 있다.
- 샤딩을 적용하기전에 가능한 샤딩을 피하는 방법을 고려해보자 !
샤딩적용하기전
- 샤딩을 적용하면 프로그래밍, 운영적인 복잡도가 증가
- scale-in을 통해 저 좋은 컴퓨터를 사용해서 샤딩을 피하자
- read부하가 크면? cache나 db replication을 사용.
- table의 일부컬럼만 자주사용하면? vertically partition을 사용하거나 데이터를 hot, warm, cold로 분리.
샤딩에 필요한 원리
- 분산된 DB에서 Data를 어떻게 read할 것인가?
- 데이터를 어떻게 잘 분산시켜 저장할 것인가? => 분산이 잘 안되면 한쪽으로 데이터가 몰리고 Hotspot이 생겨서 느려진다.
Shard Key를 어떻게 정의하느냐에 따라 데이터를 효율적으로 분산시키는 것이 결정 !
Hash Shad
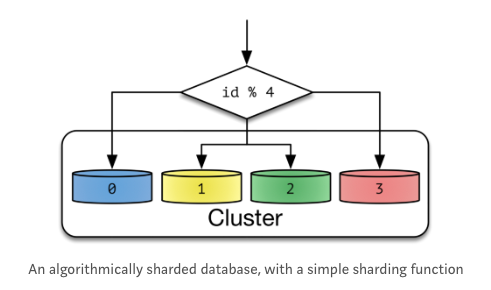
- 샤딩함수를 이용한다. partition key를 DB id로 바꾼다. “hash(key) & NUM_DB”
- DB id를 해싱하여 결정. 해쉬의 크기는 cluster안에 있는 node의 갯수로 정한다. 간단해서 좋다
고려사항
- cluster가 포함하는 node의 갯수가 늘어나거나 줄어들면? hash의 크기가 변하게 되고, hash-key 또한 변한다. 이때 기존에 분산된 rule이 붕괴되고 reshading이 필요하다.
- 짝수번째 cluster에 큰 데이터만 들어가면? hash key로 분산되기 때문에 공간에 대한 효율성이 고려되지 않는다.
dynamic shading
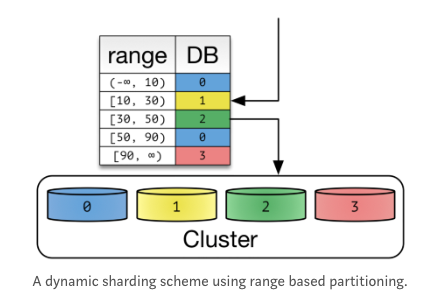
- 동적으로 바꿀 수 있다.
- Locator service를 통해 shad key를 얻는다.
- cluster가 포함된 node 갯수가 바뀌면? locator service에 shad key를 추가하면 된다. 기존 data의 shad key는 변경이 없다. 확장에 유연.
- 위에 나와있는 range,DB를 표시하는게 locator service인가?
고려사항
- data relocation을 하게되면? locator service의 shad table도 일치시켜야된다.
- locator가 성능을 위해 cache하거나 replication을 하면? 잘못된 routing을 통해 data를 찾지 못하고 error가 발생.
reference
- https://nesoy.github.io/articles/2018-05/Database-Shard
- https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Database/%5BDB%5D%20Key.md
Written on February 4, 2020