2020-4-4 스프링 Data common (1)
JPA
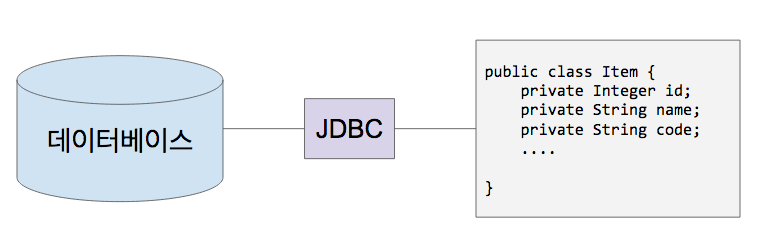
- java에서는 JDBC(Java Database Connection)이라는걸 사용해서 DB에 연결할 수 있다.
docker run -p 54320:5432 -e POSTGRES_PASSWORD=1234 -e POSTGRES_USER=jimmy -e POSTGRES_DB=jpa-test --name postgre_boot -d postgres
$docker exec -it container_name bash
$su -u postgres
java와 sql
- DDL : 데이터를 정의, 스키마를 만든다.
- DML :
@SpringBootApplication
@PropertySource("classpath:application.properties")
public class DemoApplication {
@Value("${db.username}")
private String username;
@Value("${db.password}")
private String password;
public static void main(String[] args) throws SQLException {
SpringApplication.run(DemoApplication.class, args);
String url = "jdbc:postgresql://localhost:54320/jpa-test";
String username = "jimmy";
String password="1234";
try (Connection connection = DriverManager.getConnection(url, username, password)){
System.out.println("Connection created: " + connection);
String sql = "insert into ACCOUNT values (1, 'docker', '123')";
try(PreparedStatement statement = connection.prepareStatement(sql)) {
statement.execute();
}
}
}
}
- 이렇게 데이터를 다루는게 굉장히 번거롭다.
- connection을 만드는 비용이 비싸고 오래걸린다.
- sql이 DB마다 다르다. 그래서 Postgre => mysql로 가면 코드를 다 바꿔야된다.
- 중복된 코드가 많다.
ORM(Object-Relation Mapping)
- ORM은 클래스와 SQL 데이터베이스 테이블 사이의 맵핑정보를 기술한 메타데이터를 사용한다. 애플리케이션 객체를 SQL 데이터베이스 테이블에 자동으로 깔끔하게 영속화해준다.
JDBC대신 도메인 모델 사용하려는 이유는?
- 객체 지향 프로그래밍의 장점을 활용
- 각종 디자인패턴
- 코드 재사용
- 비즈니스 로직 구현 및 테스트 편하다.
장점
- 생산성
- 유지보수성
- 성능 : 더 느릴수도 있다. 하지만 C가 자바보다 빠르다라는 맥락하고 비슷하다. 객체와 데이터베이스 사이에 캐시가 존재하기 때문에 불필요한 쿼리를 날리지 않는다. 여러번 동일한 쿼리를 날리면 캐시에서 디비에 변경사항을 반영하느냐 안하느냐를 결정한다.
- 벤더 독립성 : mysql, postgresql 등으로 변경이 손쉽다. dialect(방언)을 설정하기만 하면 hibernate는 그 dialect에 맞는 sql을 생성한다.
단점
- 학습비용
ORM 패러다임 불일치
밀도의 문제
- 객체
- 다양한 크기의 객체를 만들 수 있다.
- 커스텀한 타입 만들기 쉽다.(primitive가 아닌 사용자 정의 클래스를 말한다)
- 릴레이션
- 테이블
- 기본데이터타입(UDT는 비추)
서브타입문제
- 객체
- 상속구조 만들기 쉽다
- 다형성
- 릴레이션
- 테이블 상속이라는게 없다
- 상속기능을 구현해도 표준기술이 아니다
- 다형적인 관계를 표현할 방법이 없다
식별성문제
- 객체
- 레퍼런스 동일성
- 인스턴스 동일성(equlas()메서드)
- 릴레이션
- 주키(Primary key)
관계문제
- 객체
- 객체 레퍼런스로 관계표현
- 방향이 존재한다.
- 다대다 관계를 가질 수 있다.
- 릴레이션
- 외래키로 관계표현
- 방향이라는 의미가 없다. 그냥 Join으로 아무거나 묶을 수 있다. => 외래키는 방향이 없다. 사실상 양방향
- 다대다관계를 태생적으로 못만들고 조인테이블 또는 링크 테이블을 사용해서 두개의 1대다 관계로 풀어야한다.
데이터 네비게이션 문제
가장 복잡하고 성능에 영향을 많이준다.
- 객체
- 레퍼런스를 이용해서 다른 객체로 이동 가능
- 콜렉션을 순회할 수도 있다.
- 릴레이션
- 원하는데이터를 가져오는데 매우 비효율적. 데이터베이스에 요청이 적게하기 위해 Join을 하는데 이 역시도 문제. => SQL에서 커넥션을 만드는게 큰 비용인데, 많은 Join을 해도 문제다.
- n+1 select문제가 발생
Written on April 4, 2020